“I Built a Multi-Agent System on NemoClaw. Then My Brev Credits Ran Out.”
— Medium, developer experience report, March 2026
NemoClaw is NVIDIA’s enterprise security wrapper for OpenClaw — the open-source AI agent framework that combines kernel-level sandboxing via OpenShell, a YAML policy engine for per-action authorization, and a privacy router for local inference. While most NemoClaw guides focus on single-agent deployments, the production use case that enterprises actually need is multi-agent: a supervisor agent that decomposes complex tasks and dispatches them to specialized worker agents, each running in its own sandboxed environment with its own YAML policy.
This guide covers multi-agent deployment on NemoClaw — the supervisor-worker architecture, framework integration through NeMo Agent Toolkit v1.5.0, per-agent policy isolation, audit logging across agent boundaries, and the production access controls required for Phase 3 enterprise deployment. If you have completed a single-agent NemoClaw setup from our Implementation Guide, this is the next step toward production-scale automation.
The multi-agent landscape is evolving rapidly. The CrewAI blog published “Orchestrating Self-Evolving Agents with CrewAI and NVIDIA NemoClaw” in March 2026. The NeMo Agent Toolkit v1.5.0 added native integrations with LangChain, LlamaIndex, CrewAI, Semantic Kernel, and Google ADK. The frameworks exist. The hard part is not orchestration — it is security isolation, audit trails, and access controls at scale. That is what this guide addresses.
Supervisor + Worker: The Core Pattern
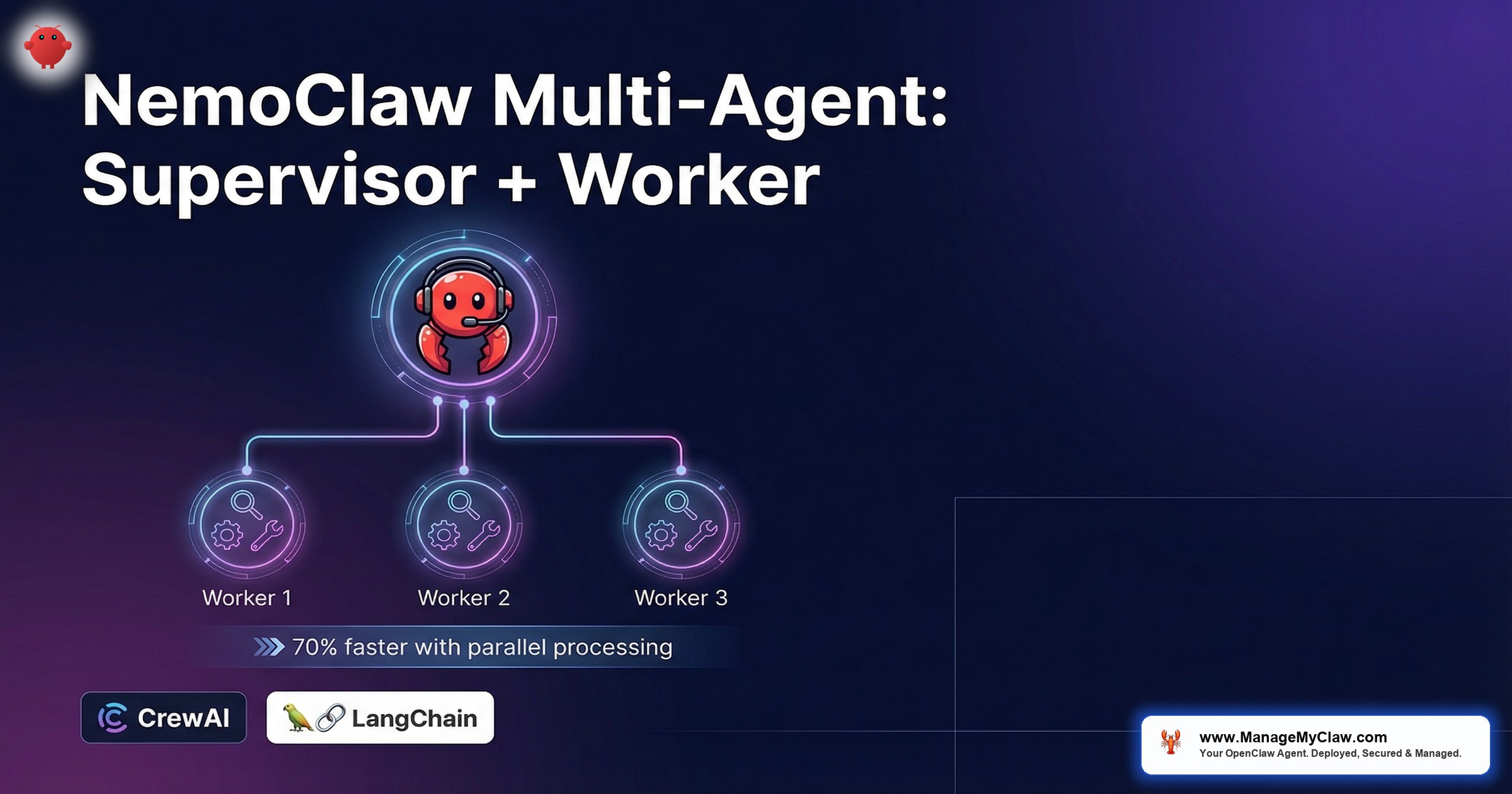
The supervisor-worker pattern separates decision-making from execution. The supervisor agent receives a complex task, decomposes it into subtasks, and dispatches each subtask to a specialized worker agent. Each worker runs in its own NemoClaw sandbox with its own YAML policy. The supervisor has read access to all workers’ outputs but cannot directly access the APIs or tools that workers use. According to Oflight’s analysis of multi-agent architectures, the supervisor-worker pattern reduces processing time by up to 70% compared to single-agent execution on complex, decomposable tasks — the parallelism gains compound as worker count increases.
| Role | Permissions | Sandbox | Policy |
|---|---|---|---|
| Supervisor | Read worker outputs, dispatch tasks, aggregate results | Own sandbox — minimal network access | Can reach inference API + internal task queue only |
| Worker: Email | Read Gmail API (GET only), write to output directory | Isolated sandbox — email API access only | gmail.googleapis.com GET, /sandbox/output/ write |
| Worker: Slack | Post messages to specific channels, read channel history | Isolated sandbox — Slack API access only | slack.com POST to /api/chat.postMessage only |
| Worker: Data | Query read replica database, write reports to output | Isolated sandbox — database access only | db-replica.internal:5432 TCP, /sandbox/output/ write |
The security advantage is clear: if the email worker is compromised through prompt injection, the attacker gains access to the Gmail API — but not to Slack, not to the database, and not to the supervisor’s task queue. Each worker’s blast radius is limited to its own policy boundary. The supervisor cannot be used as a lateral movement path because it has no direct API access.
Running multiple agents in a single NemoClaw sandbox means all agents share the same YAML policy — the same network destinations, the same binary allowlist, the same filesystem paths. A compromised email agent inherits the database agent’s database credentials and the Slack agent’s posting permissions. This is exactly the excessive agency risk that OWASP ASI01 describes. Always deploy one sandbox per agent in multi-agent architectures.
NeMo Agent Toolkit v1.5.0: Framework Integrations
NVIDIA’s NeMo Agent Toolkit v1.5.0 provides the glue between popular agent frameworks and NemoClaw’s security infrastructure. Instead of building custom integration code, the toolkit offers pre-built connectors that route framework operations through NemoClaw’s sandbox and policy engine. The v1.5.0 release integrates with five major frameworks: LangChain, LlamaIndex, CrewAI, Semantic Kernel, and Google ADK. Notably, the supervisor pattern is compatible with LangGraph and CrewAI orchestration features, making migration from existing LangGraph or CrewAI deployments straightforward — you add NemoClaw sandbox isolation without rewriting your orchestration logic.
| Framework | Toolkit Integration | Multi-Agent Support |
|---|---|---|
| LangChain | NemoClawSandboxTool, NemoClawCallbackHandler | AgentExecutor per worker, shared memory via supervisor |
| LlamaIndex | NemoClawQueryEngine, sandboxed tool calling | SubQuestionQueryEngine maps to worker agents |
| CrewAI | NemoClawAgent base class, task routing to sandboxes | Native Crew supervisor-worker pattern |
| Semantic Kernel | NemoClawPlugin, sandboxed function calling | Planner dispatches to sandboxed plugins |
| Google ADK | NemoClawToolkit, sandbox-aware action execution | Multi-agent orchestration via ADK routing |
CrewAI + NemoClaw: Production Example
CrewAI’s architecture maps naturally to the supervisor-worker pattern. A “Crew” contains multiple agents with defined roles, and CrewAI’s task routing determines which agent handles each subtask. With NemoClaw integration, each CrewAI agent runs in its own sandbox.
# crew_setup.py — CrewAI with NemoClaw sandbox isolation
from crewai import Agent, Task, Crew, Process
from nemo_agent_toolkit.nemoclaw import NemoClawSandbox
# Each agent gets its own NemoClaw sandbox with a specific policy
email_sandbox = NemoClawSandbox(
policy="policies/workers/email-readonly.yaml",
name="worker-email",
memory_limit="2g"
)
slack_sandbox = NemoClawSandbox(
policy="policies/workers/slack-poster.yaml",
name="worker-slack",
memory_limit="1g"
)
data_sandbox = NemoClawSandbox(
policy="policies/workers/db-readonly.yaml",
name="worker-data",
memory_limit="2g"
)
# Define agents with sandbox isolation
email_agent = Agent(
role="Email Analyst",
goal="Summarize unread emails from the last 24 hours",
sandbox=email_sandbox,
verbose=True
)
slack_agent = Agent(
role="Slack Reporter",
goal="Post daily briefing to #executive-updates",
sandbox=slack_sandbox,
verbose=True
)
data_agent = Agent(
role="Data Analyst",
goal="Query yesterday's KPIs from the analytics database",
sandbox=data_sandbox,
verbose=True
)
# Supervisor crew — sequential process with human approval
daily_briefing = Crew(
agents=[email_agent, data_agent, slack_agent],
tasks=[
Task(description="Fetch email summaries", agent=email_agent),
Task(description="Query KPI dashboard", agent=data_agent),
Task(description="Compile and post briefing", agent=slack_agent),
],
process=Process.sequential,
verbose=True
)
result = daily_briefing.kickoff()“Orchestrating Self-Evolving Agents with CrewAI and NVIDIA NemoClaw.”
— CrewAI Blog, official NemoClaw orchestration guide, March 2026YAML Policies for Each Agent Role
Each worker agent needs its own YAML policy that grants exactly the permissions its role requires — nothing more. The supervisor agent’s policy is the most restrictive: it can reach the inference API and the internal task queue, but it cannot access any external service directly.
# Supervisor: inference + task queue only
# Cannot access external APIs — delegates to workers
name: supervisor-agent
version: "1.0"
binaries:
allow:
- python3
network:
destinations:
# Inference endpoint only
- host: inference.local
port: 11434
methods: [POST]
paths:
- /v1/chat/completions
# Internal task queue (Redis or similar)
- host: taskqueue.internal
port: 6379
protocol: tcp
filesystem:
read:
- /sandbox/config/
- /sandbox/worker-outputs/ # Read worker results
write:
- /sandbox/output/
- /tmp/# Email Worker: Gmail read-only + OAuth refresh
name: worker-email
version: "1.0"
binaries:
allow:
- python3
network:
destinations:
- host: gmail.googleapis.com
methods: [GET]
paths:
- /gmail/v1/users/me/messages
- /gmail/v1/users/me/messages/*
- host: oauth2.googleapis.com
methods: [POST]
paths:
- /token
- host: inference.local
port: 11434
filesystem:
read:
- /sandbox/config/
write:
- /sandbox/output/email-summaries/
- /tmp/Audit Logging Across Agent Boundaries
In a multi-agent deployment, the audit trail must capture which agent made which request, when, and whether it was allowed or denied. NemoClaw’s policy engine logs every authorization decision with the sandbox ID, enabling per-agent audit trails from a single log stream.
# All policy decisions for the email worker
$ nemoclaw logs --component policy --filter sandbox_id=worker-email --tail 50
# All DENY decisions across all agents
$ nemoclaw logs --component policy | grep "DENY"
# Export structured audit log for compliance (JSON format)
$ nemoclaw audit export \
--format json \
--start "2026-03-20T00:00:00Z" \
--end "2026-03-20T23:59:59Z" \
--output audit-$(date +%Y%m%d).json
# Sample audit log entry:
# {
# "timestamp": "2026-03-20T14:32:01Z",
# "sandbox_id": "worker-email",
# "action": "ALLOW",
# "binary": "python3",
# "destination": "gmail.googleapis.com",
# "method": "GET",
# "path": "/gmail/v1/users/me/messages",
# "policy": "workers/email-readonly.yaml"
# }Centralized Logging for SOC Integration
For enterprise SOC (Security Operations Center) integration, export NemoClaw’s audit logs to your SIEM (Splunk, Elastic, Datadog) via syslog or structured JSON output. Each log entry includes the sandbox ID, which maps to a specific agent role in your multi-agent architecture.
# Configure NemoClaw to forward audit logs to syslog
$ nemoclaw config set audit.syslog.enabled true
$ nemoclaw config set audit.syslog.endpoint "siem.internal.company.com:514"
$ nemoclaw config set audit.syslog.format "json"
$ nemoclaw config set audit.syslog.facility "auth"
# Restart to apply
$ nemoclaw restart
# Verify syslog output
$ nemoclaw logs --component audit | head -5Production Deployment: Access Controls and Governance
Phase 3 production deployment adds the governance layer that alpha deployments skip: access controls for who can create agents, modify policies, and view audit logs. Without these controls, any developer with NemoClaw CLI access can deploy an agent with arbitrary permissions.
| Deployment Phase | Access Control | Audit | Approval Workflow |
|---|---|---|---|
| Phase 1: Development | Developer self-service | Local logs only | None — rapid iteration |
| Phase 2: Staging | Team-level access | Centralized logging | Peer review for policy changes |
| Phase 3: Production | Role-based (RBAC), MFA | SIEM integration, retention policy | Security team approval for new agents and policy changes |
RBAC for Multi-Agent Deployments
# Define roles for multi-agent management
$ nemoclaw rbac create-role agent-operator \
--permissions "sandbox:create,sandbox:start,sandbox:stop,sandbox:logs" \
--description "Can deploy and manage agent sandboxes"
$ nemoclaw rbac create-role policy-admin \
--permissions "policy:read,policy:write,policy:reload,policy:delete" \
--description "Can create and modify YAML and Rego policies"
$ nemoclaw rbac create-role audit-viewer \
--permissions "audit:read,audit:export" \
--description "Read-only access to audit logs"
# Assign roles to team members
$ nemoclaw rbac assign agent-operator --user alice@company.com
$ nemoclaw rbac assign policy-admin --user security-team@company.com
$ nemoclaw rbac assign audit-viewer --user compliance@company.com
# Verify role assignments
$ nemoclaw rbac list-assignmentsIn production, the person who deploys agents should not be the same person who writes policies. The agent operator role can start and stop sandboxes but cannot modify the policies that govern them. The policy admin can write rules but cannot deploy agents. This separation ensures that no single individual can deploy an agent with self-authored permissions — a basic enterprise governance requirement.
What the Community Has Learned
A developer documented building a multi-agent system on NemoClaw using Brev cloud GPU credits. The system worked — supervisor dispatched to workers, workers ran in isolated sandboxes, audit logs captured everything. Then the Brev credits ran out.
The lesson: multi-agent NemoClaw deployments multiply resource consumption linearly. Each worker sandbox consumes 1-2 GB RAM, each policy engine evaluation adds latency, and each inference call costs money. Plan your cloud compute budget for N agents, not 1 agent.
Our recommendation: run inference locally (Ollama + Nemotron) for development. Reserve cloud GPU credits for production load testing. Budget cloud costs per-agent, not per-deployment.
For the broader AI agent technology stack and how NemoClaw fits into production infrastructure, see our AI Agent Stack 2026 analysis.
“The security isolation per-agent is what makes NemoClaw worth the setup cost. Every other multi-agent framework gives you orchestration but puts all agents in the same trust boundary.”
— r/LocalLLaMA, evaluating NemoClaw vs. alternatives, March 2026Resource Planning for Multi-Agent Scale
| Deployment Size | Agents | RAM | CPU | Estimated Monthly Cost (Cloud) |
|---|---|---|---|---|
| Small (dev team) | 1 supervisor + 2 workers | 16 GB | 4 vCPU | $50-80 |
| Medium (department) | 1 supervisor + 5 workers | 32 GB | 8 vCPU | $120-200 |
| Large (enterprise) | 3 supervisors + 15 workers | 64 GB | 16 vCPU | $300-500 |
| + Local inference | Add NVIDIA GPU | +24 GB VRAM | — | +$3,999 hardware (DGX Spark) |
These estimates assume cloud API inference (OpenAI, Anthropic). Adding local inference via Nemotron requires NVIDIA GPU hardware, which changes the cost model from operational expense to capital expense. For most enterprise multi-agent deployments, we recommend starting with cloud inference during Phase 1-2 and migrating to local inference in Phase 3 when data sovereignty requirements demand it. See our pricing page for managed deployment costs at each scale.
Frequently Asked Questions
Can workers communicate directly with each other?
Not by default, and we recommend against it. Worker-to-worker communication creates lateral movement paths. If worker A can send data to worker B, a compromised worker A can attack worker B through its communication channel. The supervisor-worker pattern routes all inter-agent communication through the supervisor, which acts as a checkpoint. If you must enable direct worker communication, create a dedicated internal message bus with its own YAML policy and audit logging.
Which framework is best for NemoClaw multi-agent?
CrewAI provides the most natural mapping to the supervisor-worker pattern and has explicit NemoClaw documentation via the CrewAI blog. LangChain offers the most flexibility for custom orchestration logic. LlamaIndex is strongest for RAG-heavy workflows where workers retrieve and synthesize documents. Semantic Kernel integrates best with Microsoft ecosystem tools. For detailed framework comparisons, sparkco.ai published a head-to-head analysis of LangChain vs. AutoGen vs. CrewAI vs. OpenClaw, and o-mega.ai covers “LangGraph vs CrewAI vs AutoGen: Top 10 AI Agent Frameworks” with benchmark data. Choose based on your existing framework expertise and the specific workflow patterns your agents implement.
How do I handle worker failures in production?
The supervisor should implement retry logic with exponential backoff for worker failures. NemoClaw’s sandbox health check (nemoclaw sandbox health <sandbox-id>) returns the sandbox status, which the supervisor can poll before dispatching tasks. For critical workflows, configure dead letter queues: tasks that fail after N retries are routed to a human review queue rather than dropped. Our managed deployments include automated sandbox restart on failure with Slack/PagerDuty alerting.
Can I run multi-agent NemoClaw on a single machine?
Yes, for development and small deployments. A machine with 32 GB RAM and 8 CPU cores can run a supervisor and 3-4 workers comfortably. Each sandbox consumes approximately 1-2 GB RAM at idle. For production with more than 5 concurrent workers, distribute across multiple machines and use NemoClaw’s gateway clustering (when available) or a load balancer in front of multiple NemoClaw instances.