“EU AI Act reaches full enforcement in August 2026. Every AI agent that touches personal data needs a compliance story — and ‘we send everything to a cloud API’ is not one.”
Gartner projects 40% of enterprise apps will include AI agents by end of 2026. Most of those agents will process sensitive data — patient records, financial transactions, privileged legal communications, personally identifiable information. And most of those organizations will route that data to a cloud LLM provider with no classification, no filtering, and no audit trail documenting where each data element went.
That is a regulatory problem waiting to become a regulatory event. HIPAA requires covered entities to ensure electronic protected health information (ePHI) is not disclosed to unauthorized parties. SOC2 Trust Service Criteria mandate data handling controls at the system level. GDPR Article 44 restricts transfers of personal data outside the EEA. And ISO 42001 — the first international standard for AI management systems — requires vendors to guarantee that your data is excluded from model training.
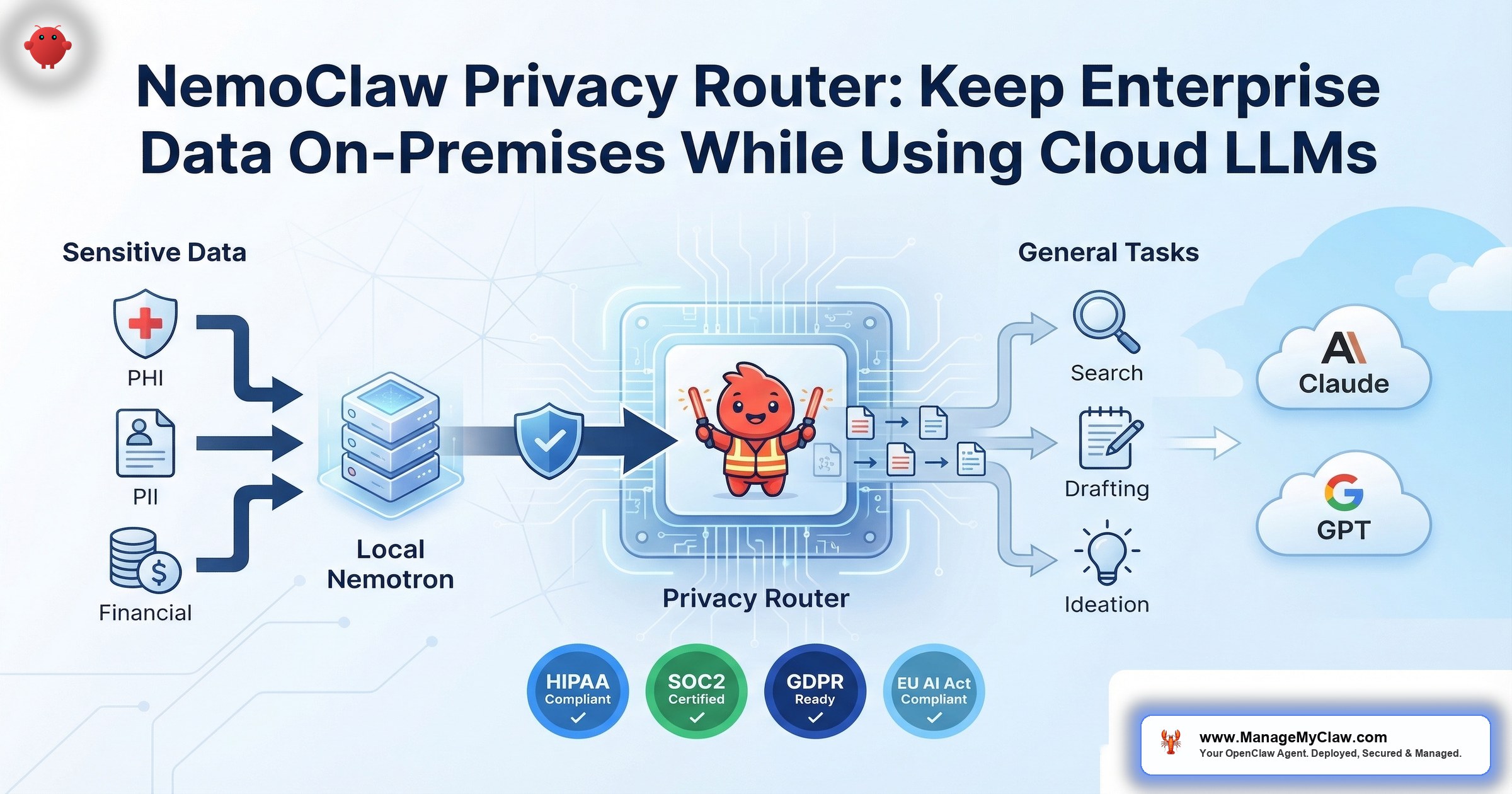
NemoClaw’s privacy router was built to solve this problem at the infrastructure layer. It intercepts every inference call your AI agent makes, classifies the data sensitivity, and routes each request to either a local Nemotron model or a cloud LLM — based on YAML-configurable routing rules that your compliance team can audit.
This post breaks down exactly how the privacy router works, maps it to specific regulatory frameworks, and walks through deployment scenarios for healthcare, finance, and legal — the three industries where getting data routing wrong carries the highest penalties.
of CISOs rank agentic AI as their #1 attack vector
EU AI Act full enforcement deadline
Why “Send Everything to the Cloud” Fails in Regulated Industries
Most AI agent deployments follow a simple architecture: the agent generates a prompt, sends it to a cloud LLM (Claude, GPT-5, Gemini), receives a response, and acts on it. Every request goes to the same endpoint. Every piece of context — including whatever sensitive data the agent has access to — leaves the organizational perimeter.
For a startup running email triage, this is fine. For a hospital system where the agent processes patient intake notes, it is a HIPAA violation. For a hedge fund where the agent summarizes trading positions, it is a data exfiltration risk. For a law firm where the agent drafts contract language from case files, it is a breach of attorney-client privilege.
The irony: organizations adopt AI agents to increase productivity, then discover that the productivity gains require sending their most sensitive data to a third-party API they do not control.
- No data classification — every request treated identically regardless of sensitivity
- No routing logic — sensitive and non-sensitive data go to the same cloud endpoint
- No audit trail — no record of which data elements left the organization
- No redaction — PII, PHI, and financial records sent in plaintext prompts
- No data residency controls — data may be processed in any jurisdiction the provider operates
The OWASP Agentic Top 10 identifies this pattern under ASI09 (Insufficient Logging) and ASI06 (Excessive Data Exposure). Without a classification and routing layer, every agent inference call is a potential compliance event. And without logging, you have no way to prove — to auditors, regulators, or your own legal team — that sensitive data stayed where it was supposed to.
How NemoClaw’s Privacy Router Works
The privacy router is one of NemoClaw’s 3 core components, alongside the OpenShell kernel-level sandbox and the YAML policy engine. Its role is specific: intercept every inference call the agent makes, evaluate the data sensitivity, and route the request to the appropriate model — local or cloud — based on configurable rules.
The Routing Pipeline
Here is what happens on every single agent request:
-
1
Interception. OpenShell mediates the request before it reaches any model provider. The agent does not have direct access to cloud APIs — every call passes through the privacy router first.
-
2
Classification. The router evaluates the request content against your routing rules. It identifies data types — PHI, PII, financial records, privileged communications — using pattern matching and classification logic defined in your YAML configuration.
-
3
Redaction. If a request is routed to a cloud model, the router strips or redacts sensitive content before transmission. PII fields, patient identifiers, account numbers — removed before the prompt reaches the external API.
-
4
Routing. Sensitive requests go to local Nemotron models running on your NVIDIA hardware. Non-sensitive requests go to frontier cloud models (Claude, GPT-5) for maximum reasoning capability. The split happens per-request, not per-session.
-
5
Logging. Every routing decision is logged — which data types were detected, which model received the request, whether redaction was applied, and the full timestamp. This creates the audit trail your compliance team needs.
The privacy router operates outside the agent at the OpenShell infrastructure layer. The agent cannot bypass, override, or modify routing rules — even if it is compromised by prompt injection or instructed to exfiltrate data. This is the same out-of-process enforcement pattern that makes OpenShell’s sandbox effective: the control point is in the runtime, not in the application.
YAML-Configurable Routing Rules
Routing rules are defined in YAML — not in code, not in agent instructions, not in prompt templates. This matters for compliance because YAML configuration files are versionable, auditable, and reviewable by non-engineers. Your compliance officer can read a routing table. They cannot read Python middleware.
The routing table specifies rules per data type. Each rule defines the data category, detection patterns, the routing destination (local or cloud), and whether redaction applies. Rules can be scoped by department, workflow, or agent instance — a healthcare organization might route differently for clinical agents versus administrative agents.
Your compliance team should be able to open a YAML file and answer: “Where does patient data go?” If they cannot, your data governance is not auditable.
Local Nemotron Models: What Runs On-Premises
Nemotron is NVIDIA’s enterprise LLM family, optimized for reasoning, instruction following, and tool use. The family includes multiple tiers for different workload requirements:
- Nemotron — the base model optimized for enterprise inference, instruction following, and tool use
- Nemotron Ultra — the advanced reasoning variant designed for complex multi-step analysis, contract review, and medical record interpretation
- Nemotron 3 Super 120B — a hybrid Mixture-of-Experts (MoE) architecture that delivers high throughput while maintaining reasoning quality at scale
All Nemotron models are supported through NVIDIA NIM (NVIDIA Inference Microservices) and vLLM, giving operations teams flexibility in deployment and serving infrastructure. When the privacy router classifies a request as sensitive, the request is processed entirely by a local Nemotron model running on your NVIDIA GPU hardware. The data never leaves your organizational perimeter.
This is not a compromise on capability for the sake of privacy. Nemotron models are purpose-built for enterprise inference workloads. They handle complex reasoning tasks — contract clause analysis, medical record summarization, financial report generation — at a level sufficient for production use. For tasks requiring frontier-level capability (creative writing, general knowledge synthesis, multi-step planning across non-sensitive domains), the router sends those to cloud models instead.
“NemoClaw is designed to let enterprises use the best model for every task — local models for sensitive data, cloud models for general reasoning — without the developer having to think about routing.”
— NVIDIA NemoClaw Documentation
The Dual-Model Architecture: Data Flow in Practice
To understand how the privacy router operates at the infrastructure level, trace a single agent session that handles both sensitive and non-sensitive tasks:
Dual Routing
Task 1: Summarize patient intake form. The agent reads the intake form containing patient name, DOB, SSN, diagnosis codes, and medication history. Privacy router detects PHI. Routes to local Nemotron model. Data never leaves hospital network. Logged as: LOCAL | PHI detected | Nemotron-70B | timestamp.
Task 2: Draft a follow-up email template. The agent generates a generic appointment reminder template with no patient-specific data. Privacy router classifies as non-sensitive. Routes to Claude via cloud API. Logged as: CLOUD | No sensitive data | Claude | timestamp.
Task 3: Analyze lab results against treatment guidelines. Lab results contain patient identifiers and medical data. Privacy router detects PHI. Routes to local Nemotron model. Treatment guidelines (publicly available) processed alongside. All inference happens on-premises.
Task 4: Research latest drug interaction studies. General medical research with no patient data. Routes to GPT-5 via cloud API for maximum knowledge breadth. Logged as: CLOUD | No sensitive data | GPT-5 | timestamp.
Result: 4 tasks. 2 processed locally (PHI present). 2 processed via cloud (no PHI). Full audit trail for every routing decision. HIPAA compliance maintained without sacrificing cloud model capability.
The critical insight: this is per-request routing, not per-agent routing. A single agent can use both local and cloud models within the same session, within the same workflow. The routing decision happens at the data level, not the deployment level. You do not need separate agents for sensitive and non-sensitive tasks.
Regulatory Compliance Mapping: How the Privacy Router Addresses Specific Requirements
Compliance officers do not need architecture diagrams. They need a mapping between regulatory requirements and technical controls. Here is how the privacy router maps to the frameworks your organization is measured against.
| Regulation | Requirement | Privacy Router Control |
|---|---|---|
| HIPAA (Security Rule) | ePHI must not be disclosed to unauthorized parties; access controls required (45 CFR 164.312) | PHI routed to local Nemotron — never reaches cloud API. Audit trail logs every routing decision for HHS/OCR review. |
| SOC2 (CC6.1) | Logical access controls over data processing; data classification required | YAML routing rules classify data by type. Per-request routing enforces access controls at the infrastructure layer. Decision logs provide SOC2 audit evidence. |
| GDPR (Article 44) | Personal data transfers outside EEA require adequate safeguards | PII detected and routed to local model — no cross-border transfer occurs. Redaction strips identifiers from cloud-bound requests. |
| EU AI Act (Aug 2026) | Transparency, human oversight, risk management for high-risk AI systems | Routing decision log provides transparency. YAML rules are human-reviewable. Per-data-type routing enables risk-proportionate controls. |
| ISO 42001 | Vendors must guarantee data is excluded from model training | Sensitive data processed locally — never sent to a third party. No vendor training exposure. Cloud requests use enterprise API agreements with training exclusion clauses. |
| OWASP ASI06 | Prevent excessive data exposure from AI agents | Classification layer prevents sensitive data from reaching uncontrolled endpoints. Redaction removes residual PII from cloud requests. |
| OWASP ASI09 | Sufficient logging for agent actions and data access | Every routing decision logged: data type, model, destination, redaction status, timestamp. Exportable to SIEM for correlation. |
The common thread across every regulation in that table: you must know where your data goes, you must control where it goes, and you must prove both to an auditor. The privacy router addresses all three.
of inference calls logged with routing decision, data classification, and timestamp
Deployment Scenarios by Regulated Industry
Healthcare: HIPAA-Compliant Agent Deployment
A health system deploys NemoClaw agents for clinical documentation and administrative workflow automation. The privacy router configuration:
- Local routing (Nemotron): Patient intake forms, lab results, discharge summaries, prescription records, any content containing patient name, DOB, MRN, SSN, diagnosis codes, or medication lists
- Cloud routing (Claude/GPT-5): Medical research queries, ICD-10 code lookups, insurance policy interpretation, appointment template generation, staff scheduling optimization
- Redaction applied: If a cloud-bound request contains residual patient identifiers, the router strips them before transmission
- Audit evidence: Routing logs exportable for HHS/OCR compliance review; BAA coverage maintained because ePHI never reaches cloud providers
The result: clinical agents with full frontier-model capability for general tasks, strict data sovereignty for anything touching patient records. No HIPAA Business Associate Agreement required with cloud LLM providers for the sensitive data path — because that data path is entirely on-premises.
The privacy router addresses data-in-transit routing — a critical technical control. But HIPAA compliance is a multi-layered organizational obligation. A compliant deployment also requires: a signed Business Associate Agreement (BAA) with every vendor in the data path, encryption at rest for all stored ePHI, comprehensive audit logging beyond routing decisions, role-based access controls for all systems touching patient data, documented workforce training on HIPAA policies, and a formal risk analysis per 45 CFR 164.308(a)(1). The fact that use-apify.com has already published a “HIPAA-Compliant OpenClaw Deployment for Healthcare Teams (2026)” guide demonstrates real market demand for this deployment pattern — and underscores the complexity of getting it right.
Finance: SOC2 and Data Residency for Trading Firms
A quantitative trading firm deploys NemoClaw agents for market analysis and document processing. The privacy router configuration:
- Local routing (Nemotron): Trading positions, client portfolio data, internal risk models, P&L reports, proprietary algorithm parameters, client account numbers
- Cloud routing (Claude/GPT-5): Public market research, SEC filing summarization, general document drafting, regulatory FAQ lookups, onboarding template generation
- Redaction applied: Client names and account numbers stripped from any summarization request routed to cloud
- Audit evidence: SOC2 CC6.1 evidence package generated from routing logs; data classification rules reviewed quarterly
Financial services firms face a specific constraint: proprietary trading data is competitively sensitive, not just regulatory sensitive. If a cloud provider’s model trains on your prompt data — even under an enterprise agreement — your trading signals could theoretically leak into the model’s weights. Local Nemotron inference eliminates this vector entirely.
Legal: Privileged Communications and Case File Protection
A mid-size law firm deploys NemoClaw agents for contract review and case research. The privacy router configuration:
- Local routing (Nemotron): Case files, client communications, deposition transcripts, settlement negotiations, anything subject to attorney-client privilege or work-product doctrine
- Cloud routing (Claude/GPT-5): Case law research, statutory interpretation, court procedure lookups, template language drafting, CLE research summaries
- Redaction applied: Client names, case numbers, and opposing party identifiers stripped from any cloud-bound request
- Audit evidence: Routing logs demonstrate that privileged material never left the firm’s infrastructure — critical for privilege challenge defense
If privileged communications are sent to a third-party cloud API, the privilege may be waived. Courts have held that disclosure to a third party — even unintentional — can constitute a waiver. The privacy router’s local routing for privileged material prevents this by ensuring the data never reaches a third-party system. This is not just a security measure — it is a professional responsibility safeguard.
Customer Support: Privacy-First AI Agent Deployment
An emerging use case documented by ChatMaxima: deploying NemoClaw-powered agents for customer support workflows where the agent handles a mix of general product questions and customer-specific account data. The privacy router configuration:
- Local routing (Nemotron): Customer account details, purchase history, payment information, support ticket context containing personal identifiers, complaint records with customer PII
- Cloud routing (Claude/GPT-5): Product knowledge base queries, FAQ generation, return policy interpretation, general troubleshooting guidance, knowledge article drafting
- Redaction applied: Customer names, email addresses, phone numbers, and order IDs stripped from any cloud-bound request
- Audit evidence: Routing logs demonstrate PII handling compliance for GDPR Article 44 and CCPA requirements
The customer support use case demonstrates that the privacy router is not limited to heavily regulated industries. Any organization that handles customer data at scale — e-commerce, SaaS, telecommunications, hospitality — benefits from a routing layer that keeps personal data on-premises while leveraging cloud model capability for general reasoning tasks.
Privacy Router in the Full NemoClaw Security Stack
The privacy router does not operate in isolation. It is one layer of a defense-in-depth architecture that includes OpenShell’s kernel-level sandbox and YAML policy engine. Here is how the three components work together:
| Layer | Component | What It Controls |
|---|---|---|
| Isolation | OpenShell Sandbox | Kernel-level process isolation. Agent cannot escape its container, access host filesystem, or escalate privileges. Enforced at the OS level. |
| Policy | YAML Policy Engine | Binary, destination, method, and path-level permission control. Deny-by-default. Credential management and tool access governed by auditable YAML rules. |
| Data Privacy | Privacy Router | Per-request data classification, sensitive/non-sensitive routing, PII redaction, and full routing decision audit trail. |
Each layer addresses a different threat model. The sandbox prevents the agent from compromising infrastructure. The policy engine prevents the agent from accessing unauthorized resources. The privacy router prevents sensitive data from leaving the organizational perimeter. Remove any one layer and you have a gap a compliance auditor will find.
CrowdStrike’s Secure-by-Design Blueprint for NemoClaw validates this layered approach. Their integration with OpenShell adds runtime threat detection — CrowdStrike Falcon AIDR monitors agent behavior for indicators of compromise while the privacy router handles data classification. The result is a security posture where both data flow and agent behavior are governed, monitored, and logged.
What the Privacy Router Requires (and Where It Falls Short)
Honest assessment. The privacy router is a genuine innovation for enterprise data sovereignty. But it has constraints your team should understand before committing to a deployment plan.
Hardware Requirements
Full privacy router functionality requires NVIDIA GPU hardware for local Nemotron inference. Without a local GPU, there is no local model to route sensitive data to — the entire value proposition depends on having an on-premises inference capability. Minimum hardware: NVIDIA RTX workstation, DGX Spark, or DGX Station. NemoClaw system requirements: Linux, 4 vCPU, 8GB RAM minimum for the runtime — but the Nemotron models themselves require significantly more memory for production-quality inference.
Without NVIDIA GPU hardware, you can still route to local Ollama-hosted models, but with reduced reasoning performance compared to Nemotron. NemoClaw is hardware-agnostic at the software level, but the privacy router works best — and delivers its compliance value — with NVIDIA hardware running Nemotron models locally. Budget for hardware as part of your deployment TCO.
Classification Accuracy
The routing rules are only as good as your classification patterns. If your YAML configuration does not account for a specific data format — say, a proprietary internal patient identifier format — the router will not detect it. This means the initial configuration requires a thorough data audit: every sensitive data type in your organization needs a corresponding routing rule. Miss one and you have an unprotected data flow.
Alpha Maturity — Especially for Regulated Industries
NemoClaw shipped as early-stage alpha on March 16, 2026. NVIDIA has 17 enterprise launch partners (Adobe, Salesforce, SAP, CrowdStrike) committed to the platform, but the privacy router is iterating rapidly. Routing rule syntax, classification capabilities, and integration APIs may change between alpha and GA. Organizations deploying now should plan for configuration updates as the platform matures.
NVIDIA’s own guidance states that NemoClaw is “suitable for evaluation but not yet recommended for production deployment in regulated environments.” For healthcare, financial services, and legal organizations subject to HIPAA, SOC2, or GDPR enforcement, the current alpha status means the platform should be evaluated and governance frameworks should be built now — but production deployment with real regulated data should wait for GA or at minimum a formal risk acceptance from your compliance team.
Industry analysts have noted both the significance and the limitations of the current stage. Kiteworks observed that “Jensen Huang just defined the strategic imperative — but left the hardest part unsolved” — referring to the data governance gap between NVIDIA’s infrastructure capabilities and the organizational policies enterprises must build themselves. The Futurum Group summarized the broader trajectory: “At GTC 2026, NVIDIA stakes its claim on autonomous agent infrastructure.” The infrastructure is real. The governance is your responsibility.
The timing calculation: organizations that build their data governance framework around the privacy router now will be production-ready when NemoClaw exits alpha. Organizations that wait until GA will be 6-12 months behind in compliance documentation and operational maturity.
Deploying the Privacy Router: Implementation Approach
Privacy router deployment is not a one-day project. For regulated enterprises, the deployment path includes data classification, routing rule development, compliance validation, and ongoing optimization. Here is a realistic timeline:
-
1
Data Audit (Week 1). Inventory every data type your AI agents access. Classify each as sensitive (PHI, PII, financial records, privileged communications) or non-sensitive. Map to regulatory requirements. This is the foundation — skip it and your routing rules will have gaps.
-
2
Routing Rule Development (Week 2). Translate your data classification into YAML routing rules. Define detection patterns for each sensitive data type. Configure redaction rules for cloud-bound requests. Set up per-department or per-workflow rule scoping.
-
3
Infrastructure Deployment (Week 2-3). Deploy NemoClaw stack: OpenShell sandbox, policy engine, and privacy router. Install and configure local Nemotron models on NVIDIA hardware. Integrate with existing SIEM/SOC infrastructure for log export.
-
4
Compliance Validation (Week 3-4). Run test workflows with synthetic data. Verify routing decisions match expected behavior. Generate sample audit reports. Review with compliance team and legal counsel. Document routing logic for regulatory review.
-
5
Production Rollout + Quarterly Review (Week 4+). Deploy to production with monitoring. Review routing tables quarterly as data types evolve. Update classification patterns as new regulatory guidance is issued. Optimize local vs. cloud routing ratios for cost and performance.
ManageMyClaw’s Enterprise Implementation (Tier 2) covers this entire pipeline: data audit, routing rule development, infrastructure deployment, compliance documentation, and 30-day hypercare. For organizations that need the privacy router operational but do not have 4 weeks of specialist engineering time available internally, this is the path to deployment without pulling your DevOps team off other priorities.
Frequently Asked Questions
Does the privacy router guarantee HIPAA compliance?
No. The privacy router provides a critical technical control — routing ePHI to local models so it never reaches cloud APIs. But as independent analysis from use-apify.com notes: “NemoClaw’s sandboxing is an important technical control but HIPAA compliance requires much more: signed BAA, encryption at rest, audit logging, access controls, staff training, documented risk analysis.” HIPAA compliance is an organizational obligation, not a product feature. You still need administrative safeguards (workforce training, documented policies and procedures), physical safeguards (facility access controls), a signed Business Associate Agreement with every vendor that touches ePHI, encryption at rest and in transit, and a completed risk analysis per 45 CFR 164.308(a)(1). The privacy router addresses the data-in-transit routing component. It does not replace a compliance program.
What happens if the local Nemotron model is unavailable?
If the local model is down, the privacy router does not fail open. Requests classified as sensitive are held or denied — they are not rerouted to cloud models as a fallback. This is the correct behavior for compliance: a temporary service interruption is preferable to an uncontrolled data disclosure. Your SIEM will receive an alert for the routing failure.
Can we use the privacy router without NVIDIA hardware?
NemoClaw is hardware-agnostic at the software level. You can route to local models hosted via Ollama on non-NVIDIA hardware. However, Nemotron models are optimized for NVIDIA GPUs, and running equivalent reasoning models on CPU or alternative hardware will have significantly slower inference times. For production enterprise workloads with compliance requirements, NVIDIA hardware delivers the performance level your workflows need.
How does the privacy router handle data that is partially sensitive?
If a request contains a mix of sensitive and non-sensitive content (e.g., a general question that references a patient name), the router has two options based on your configuration: route the entire request locally (conservative approach), or redact the sensitive elements and route the sanitized request to cloud (performance-optimized approach). Most enterprise configurations default to local routing for any request containing sensitive data — the conservative approach is easier to defend in an audit.
Does the routing decision log integrate with our existing SIEM?
Yes. Routing decision logs are structured and exportable to standard SIEM platforms (Splunk, Sentinel, Elastic). Each log entry includes: timestamp, request ID, data types detected, routing decision (local/cloud/denied), model used, redaction applied (yes/no), and agent identity. This integrates into your existing security monitoring without requiring a separate log management system.
What is the latency impact of routing through the privacy router?
The classification and routing step adds milliseconds of latency — negligible compared to model inference time (which ranges from hundreds of milliseconds to seconds). The more significant latency consideration is local vs. cloud model performance: local Nemotron models on enterprise GPU hardware deliver inference times comparable to cloud APIs. The privacy router itself is not the bottleneck.
ManageMyClaw Enterprise handles data audit, routing rule configuration, Nemotron deployment, and compliance documentation. Start with a $2,500 architecture review.
Schedule Architecture Review